基础准备
开源项目地址:https://github.com/SWivid/F5-TTS
如果你喜欢一键安装包,请直接跳到后面下载一键安装包。
部署环境:
- 操作系统:Windows 11
- 显卡类型:NVIDIA RTX 4070 Ti
Cuda 的安装与介绍请查看文章:
- Windows NVIDIA 显卡驱动、cuda、cudnn 概念梳理 https://yuziyue.com/944b89a/
- Windows CUDA 与 CUDNN 的安装与版本查看详细教程 https://yuziyue.com/c290928/
conda 的安装与使用,请看这篇文章的详细介绍:https://easyeasy.me/7e90d4d/
安装 ffmpeg 音频处理工具。
winget install --id Gyan.FFmpeg -e
# 安装完成后检测是否成功
ffmpeg -version
ffprobe -version
F5-TTS 安装
使用 conda 创建并激活虚拟环境,以后的操作都在这个虚拟环境中进行。
conda create -n f5-tts python=3.10
conda activate f5-tts
# 安装 torch,如果安装成功,但是启动程序时报错,尝试调整不同的版本试试
pip install torch==2.6.0+cu124 torchaudio==2.6.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
# 安装 f5-tts
git clone https://github.com/SWivid/F5-TTS.git
cd F5-TTS
git submodule update --init --recursive
pip install -e .
# 启动程序,首次启动会自动下载对应的模型
f5-tts_infer-gradio --port 7860 --host 0.0.0.0
- 注意:
- 安装过程中网络需要稳定,科学上网是必须的。
- 启动的时候会下载模型,多等一会儿。
- 报错的时候,仔细阅读报错信息,首先切换torch版本试试,不行的话再寻求AI支持。
F5-TTS 使用
启动以后浏览器访问地址:http://127.0.0.1:7860/
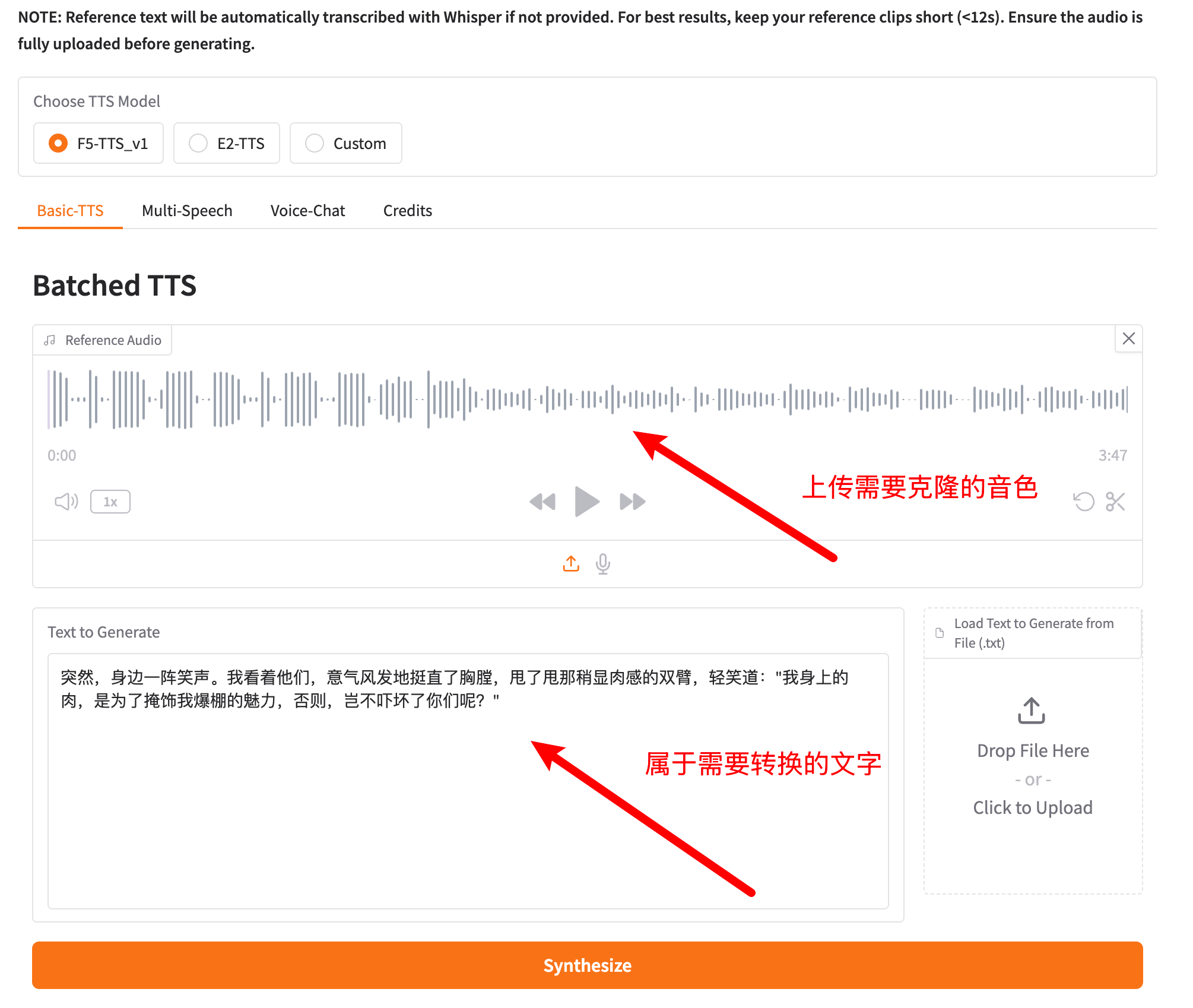
导入一段需要克隆的音色,然后输入需要转换的文字,点击 Synthesize (合成),很快就合成好了。
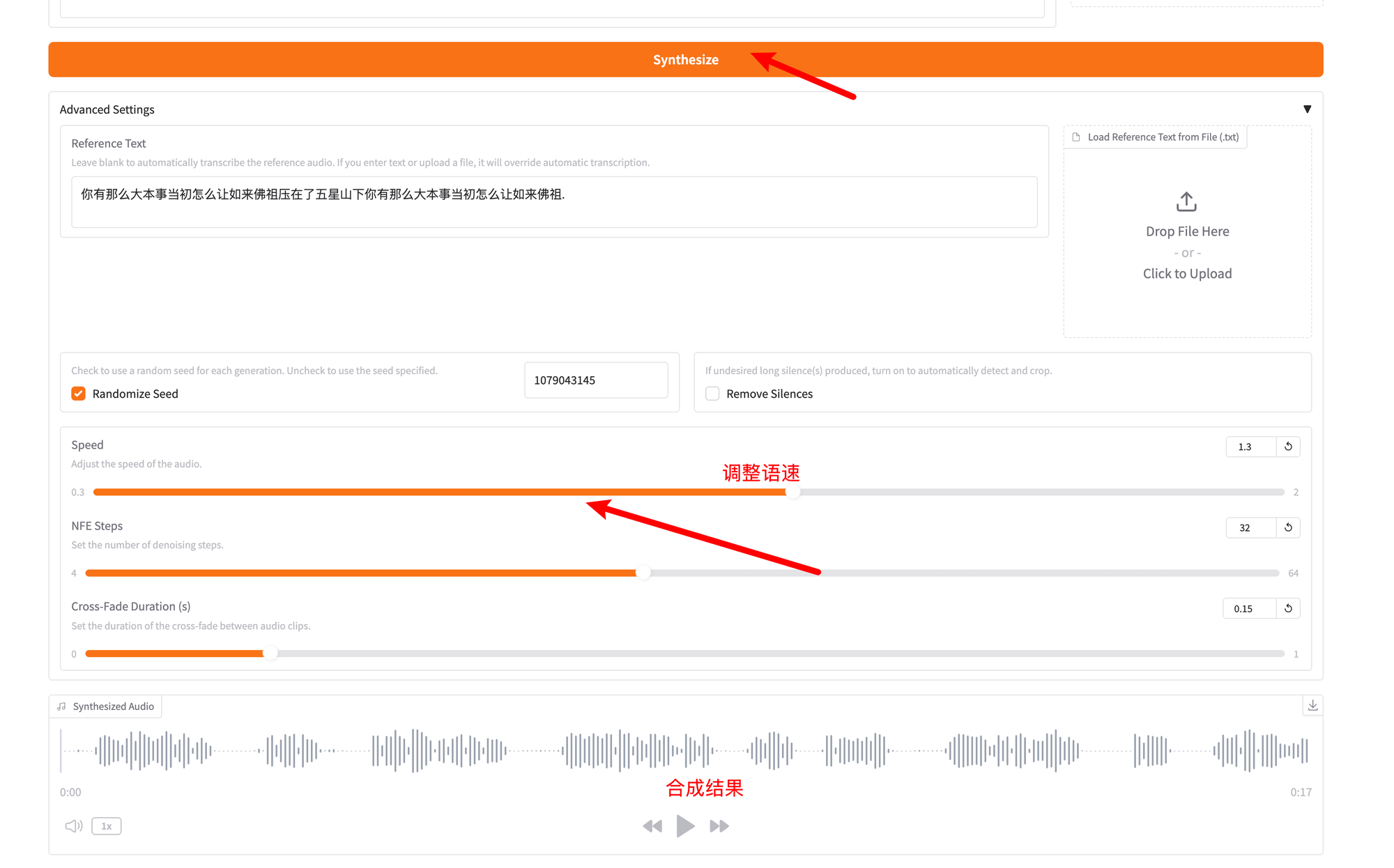
默认情况下,阅读速度可能有点慢,点击高级设置调整 Speed 即可:
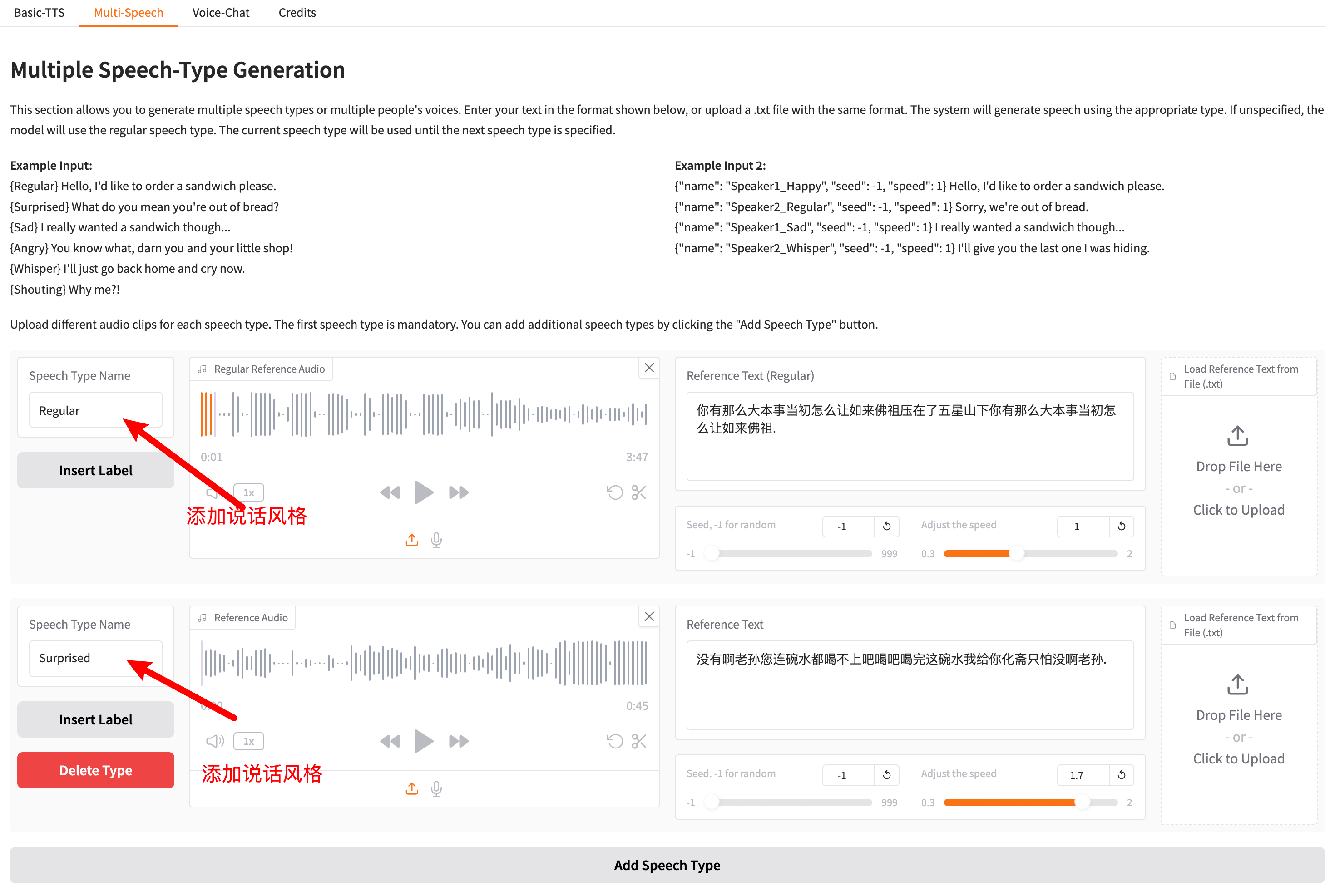
multi-speech 功能可以自定义语音,自定义喜怒哀乐的语气等等。
F5-TTS 一键安装包制作
我们使用 pyinstaller 来制作一键安装包。
# 首先在虚拟环境中安装 pyinstaller,f5-tts 的依赖 wandb 不安装后面会报错
pip install pyinstaller wandb
# 使用下面命令打包
pyinstaller.exe src\f5_tts\infer\infer_gradio.py
# 打包完成后,启动程序,此时可能报错,所以在命令行进入执行
# 此时报错是因为我们的依赖还没有添加
cd dist\infer_gradio
.\infer_gradio.exe
# 在项目根目录,修改 pyinstaller 的配置文件
# 在最后面添加参数:module_collection_mode 和 datas ,表示添加依赖
infer_gradio.spec
import os
import wandb
from PyInstaller.utils.hooks import collect_data_files
# 动态获取路径,提高可移植性
wandb_path = os.path.dirname(wandb.__file__)
vendor_path = os.path.join(wandb_path, 'vendor')
datas = [
(vendor_path, 'wandb/vendor'),
]
datas += collect_data_files('gradio_client')
datas += collect_data_files('gradio')
datas += collect_data_files('safehttpx')
datas += collect_data_files('groovy')
datas += collect_data_files('wandb')
a = Analysis(
['src\\f5_tts\\infer\\infer_gradio.py'],
pathex=[],
binaries=[],
datas=datas,
hiddenimports=['wandb', 'wandb_gql'],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
noarchive=False,
optimize=0,
module_collection_mode={'gradio':'py',}
)
修改 F5-TTS\src\f5_tts\infer\infer_gradio.py,主要是修改模型路径。
DEFAULT_TTS_MODEL_CFG = [
r'ckpts\F5TTS_v1_Base\model_1250000.safetensors',
r'src\f5_tts\infer\examples\vocab.txt',
json.dumps(dict(dim=1024, depth=22, heads=16, ff_mult=2, text_dim=512, conv_layers=4)),
]
# load models
vocoder = load_vocoder()
def load_f5tts():
ckpt_path = r'ckpts\F5TTS_v1_Base\model_1250000.safetensors'
F5TTS_model_cfg = json.loads(DEFAULT_TTS_MODEL_CFG[2])
return load_model(DiT, F5TTS_model_cfg, ckpt_path, vocab_file=r'src\f5_tts\infer\examples\vocab.txt')
def load_e2tts():
ckpt_path = r'ckpts\E2TTS_Base\model_1200000.safetensors'
E2TTS_model_cfg = dict(dim=1024, depth=24, heads=16, ff_mult=4, text_mask_padding=False, pe_attn_head=1)
return load_model(UNetT, E2TTS_model_cfg, ckpt_path, vocab_file=r'src\f5_tts\infer\examples\vocab.txt')
last_used_custom = r"infer\.cache\last_used_custom_model_info_v1.txt"
def load_last_used_custom():
try:
custom = []
with open(last_used_custom, "r", encoding="utf-8") as f:
for line in f:
custom.append(line.strip())
return custom
except FileNotFoundError:
dir_path = os.path.dirname(last_used_custom)
if dir_path and not os.path.exists(dir_path):
os.makedirs(dir_path, exist_ok=True)
return DEFAULT_TTS_MODEL_CFG
再次打包
# 保存后再执行打包,此时指定 spec 配置文件
pyinstaller.exe --clean ./infer_gradio.spec
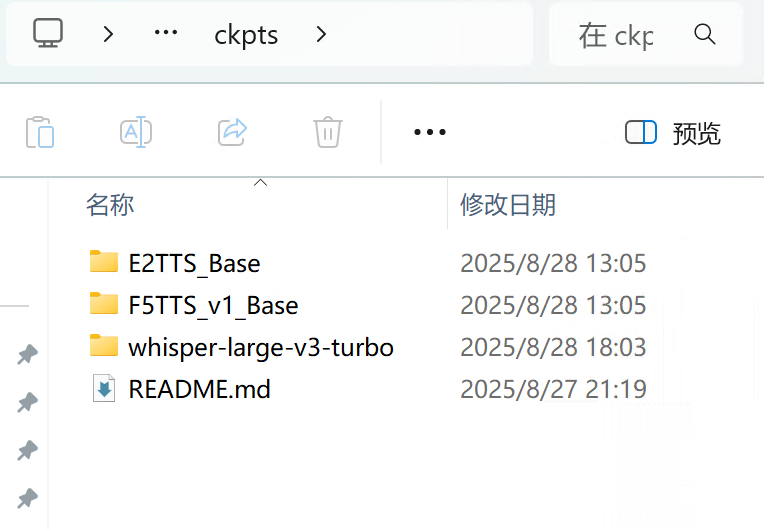
# 我们还要把模型,和必要的文件拷贝过去
ckpts
src
# 编写启动脚本
vim start_f5-tts.bat
@echo off
set PYTORCH_JIT=0
.\infer_gradio.exe --host 0.0.0.0
pause
F5-TTS 一键安装包下载地址
注意:一键安装包也需要安装一个工具,打开 cmd 命令行执行下面的命令可一键直接安装。
winget install --id Gyan.FFmpeg -e
# 安装完成后检测是否成功
ffmpeg -version
ffprobe -version- ckpts.rar 和 f5tts_infer_gradio.rar 分别解压到当前文件夹。
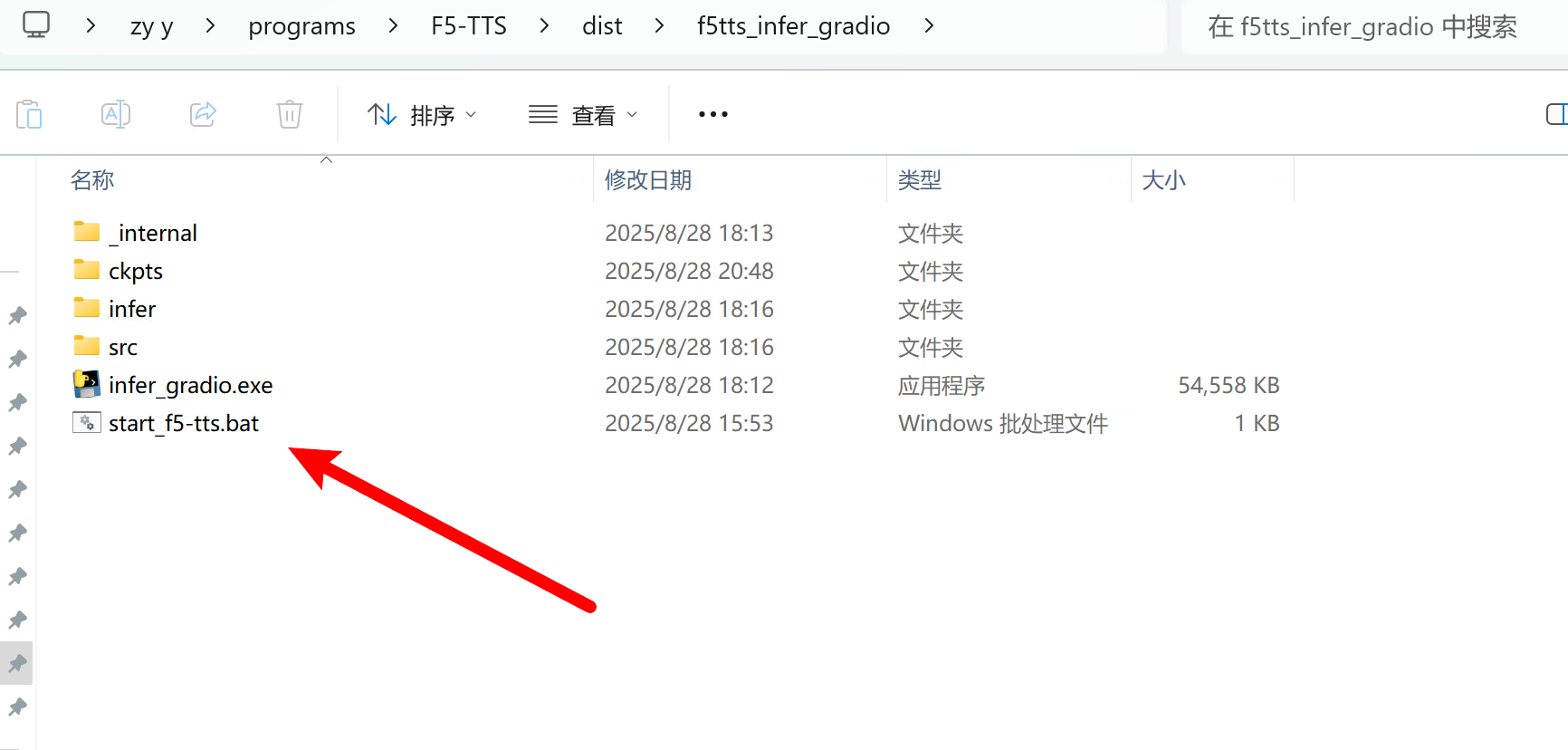
- 然后将 ckpts 目录 拖到 f5tts_infer_gradio 中。
- 双击 start_f5-tts.bat 启动查询。

下载地址:
123云盘
百度网盘
通过网盘分享的文件:f5-tts-20250828
链接: https://pan.baidu.com/s/1XRAJ4kN0aH3Sv5Q5te7n4g?pwd=v66f
提取码: v66f
--来自百度网盘超级会员v4的分享